Built by ML engineers for ML engineers with ❤️
Neptune just announced the shutdown of its services.
Let us tell you why this might actually be a good thing. We have a very good deal for you.
We will help you save lots of time and money.
We have a plug-in replacement for you. Same APIs. Just change 1 line and you're done.
Start today.
pip install minfx
import neptune
import neptune_scale
import minfx.neptune_v2 as neptune
import minfx.neptune_v3 as neptune_scaleWe will automatically migrate the data for you.
You don't have to do anything. Use all the features you're used to.
You are using machine learning in:
We are particularly aiming to optimize UI to make these as fast and easy as possible.
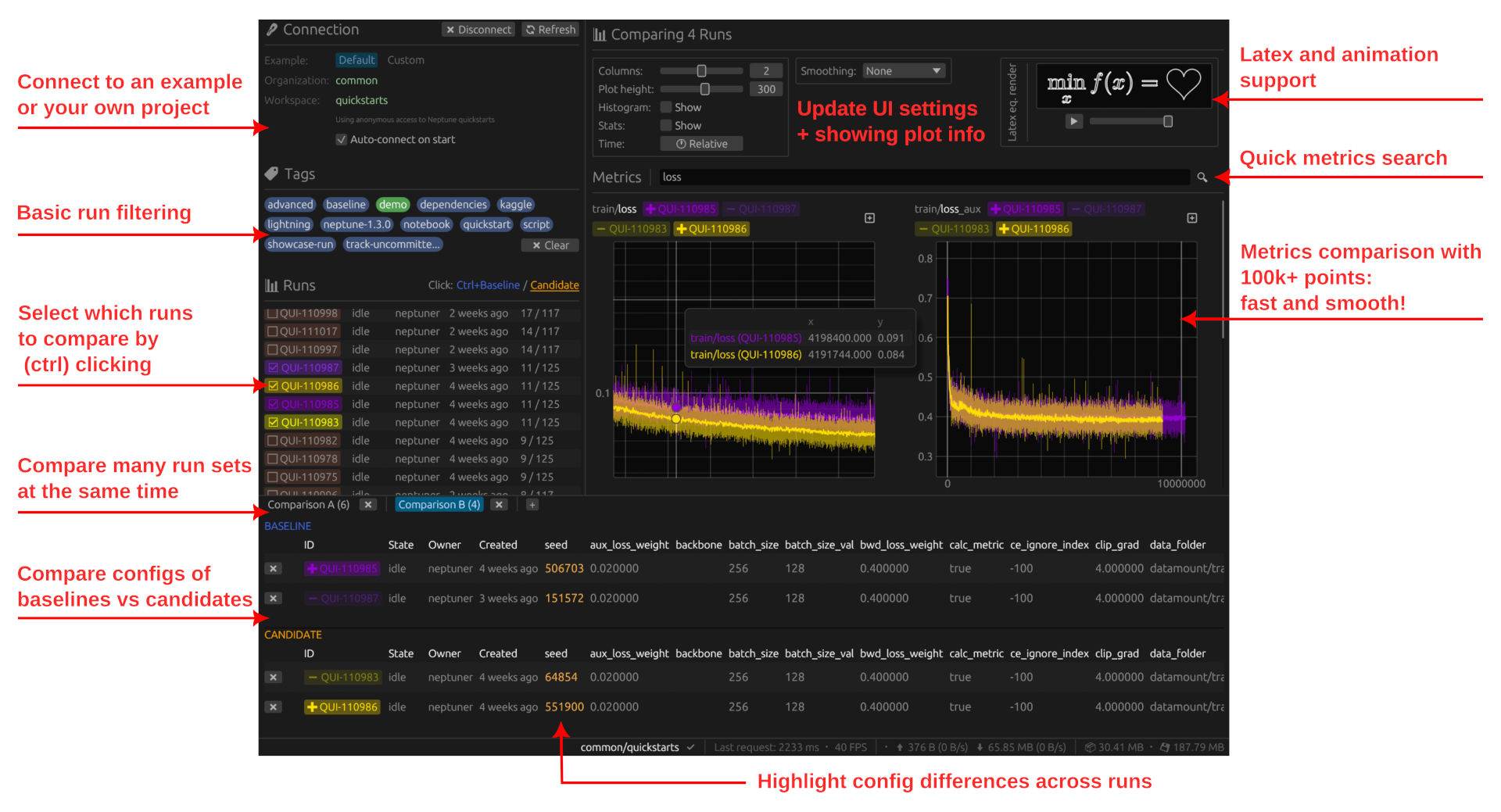
Click to enlarge
We are experts in low-level optimization, both on backend and frontend, and care very much about performance and great experience. We have been building backend for a Neptune alternative, for a few months prior to Neptune's shutdown. And now we have a push when we want to make it available to you soon.
Since Neptune is transitioning to OpenAI, we're providing current Neptune customers with dedicated support and pricing flexibility.
Email us with your Neptune project details
We'll schedule a call to discuss details and your needs in more depth
Confirm a longer-term partnership (1-3 years) with terms that work for you
Automatic data migration. Start using Minfx seamlessly.
Neptune customers only. Offer valid through January 30, 2026.
We have limited availability — only 8 seats total
We have the same API and feature parity as Neptune. So you can use your existing code with Minfx.
Additionally, we will have extra features:
WandB: In our direct experience, long time ago they used to be a good choice, but now just don't care anymore. They were acquired by Coreweave, primarily in a move to get more customers for their cloud services. They recently redesigned their UI and somehow made it worse. Their servers now often return internal 500 errors. One word: decay.
Neptune, but that's not a choice anymore.
Then there's bunch of open source stuff, that you have to self-host to get any reasonable performance and deal with all the headaches. Such as: MLFlow, AIM, LabML, etc. And of course deal with migrations, rewriting your code, etc., all in the span of 3 months.Yes, they are for starting greenfield projects. But the complexity of the spaghetti code and lack of team's understanding of the code will bite you later on. There are "fun" things to deal with, such as:
When these happen, what will you do? Do you have the people who are domain experts who can then dive in and fix the mess? This decision will cost you best-case tens of thousands of dollars.
Not yet, but we are working hard on that. You will be able to use an API mid-January.
No, we don't have SOC2 certification yet.
We are early. But we are very experienced engineers, and have been working on a very similar project prior to Neptune's shutdown.
We have lots of backend code already written, and we are now mostly working on hooking up to full Neptune's APIs, automating migration tools, and UI.
Our team includes experienced ML engineers, who have worked at Tower Research Capital (algo-trading), processing petabytes of data at scale. We have strong academic and research credentials (PhD in Machine Learning, DeepMind). Finally, the team includes a founder of DataChine (real-time data processing), with deep expertise in building high-performance data systems and a strong focus on low-level optimization.
| ✅ Done | Neptune Demo, API client basics, data migration tools |
| 🚧 In Progress | Full API compatibility, UI, production infrastructure |
| 📅 Planned | Launch on Jan 30th, additional features and integrations |
Even though we have enough engineering resources, we are happy to talk with talented people to join our team.
If you stumbled upon this page and you ❤️ what we're building, reach out to us. Find the right e-mail address 🧩 to send your application. In the subject line write "Crate: <your-crate-published-on-crates.io-here>". This is a strong requirement, without it we won't consider your application.